Building Responsible AI for Jobseekers: Model Evaluation of Compass
How do we ensure Compass produces accurate, safe outputs for jobseekers? LLMs can hallucinate skills, reinforce biases, or miss critical information—any of which could harm the users we serve. This post breaks down our seven-stage approach to model evaluation, which evolved alongside Compass itself. We started with end-to-end testing and added targeted validation as we discovered what needed to work—from synthetic queries testing taxonomy matching to manual review of over 1,000 real conversations. Read more about how we built evaluation into every stage of development.
Contributors
Anselme Irumva, Apostolos Benisis, Bereket Terefe, Giulia Moretti, Noella Fides

This is part one of a three-part series on how Tabiya evaluates Compass, our open-source AI-powered skills discovery tool for young jobseekers.
Compass helps jobseekers discover their skills through natural conversation. Users describe their work experiences—paid jobs, informal work, care work, personal projects—and Compass identifies their transferable skills, linking them to relevant occupations. In the future, the same approach that infers skills could eventually surface career preferences, learning styles, or other insights about the user.
At Tabiya, we believe that rigorous evaluation is essential for building AI that actually works for the communities we serve. The Agency Fund recently published a framework for evaluating AI in the social sector (reflecting broader momentum in the field) that maps well onto our work. We’ve found it provides a very useful structure for organizing how we discuss our evaluation practices. Their four-level approach breaks down evaluation into:
- Model Evaluation – Does the AI model produce the desired responses?
- Product Evaluation – Does the product facilitate meaningful interactions?
- User Evaluation – Does the product positively support users’ thoughts, feelings, and actions?
- Impact Evaluation – Does the product improve development outcomes?
This first post focuses on Level 1: Model Evaluation. Future posts will explore how we think about Compass product/user testing in Kenya and impact evaluation in South Africa.
Why Model Evaluation Matters
A jobseeker who receives inaccurate skills feedback might miss relevant opportunities or lose confidence in their abilities. Biased outputs could reinforce stereotypes. Hallucinated skills could undermine trust entirely. And large language models (LLMs)—the technology powering Compass—are particularly prone to these risks.
LLMs are powerful but unpredictable. They generate fluent responses by predicting the next word in a sequence, not by “understanding” in a human sense. They can sound authoritative while being wrong. Before deploying Compass to thousands of users, we needed to verify that it reliably performed its intended tasks—extracting accurate information, staying on track, and producing outputs that users could actually use. That is where structured model evaluation comes in. In this post, we explain how Compass works, the safeguards we’ve built in, and the seven-stage evaluation process we use to ensure it performs safely and accurately.
Compass’s Modular Design: Breaking Conversations into Steps
Compass doesn’t function as a single chatbot. Instead, it mimics how a career counselor would approach a conversation with a jobseeker, breaking the interaction into distinct steps, each with a specific purpose. (Technically: Compass uses agentic workflows – see our previous post for a detailed technical description.)
- A coordinating system (an “Agent Director”) manages the conversation flow, directing specialized components to handle specific tasks: welcoming the user, gathering work experience details, exploring skills, and linking them to occupations from our taxonomy.
- Each component adapts based on what the user has shared so far, making the conversation feel natural and responsive. (Technically: agents maintain internal state and draw on conversation history.)
- Once all information is collected, the system processes it to identify the user’s top transferable skills.
This modular design makes Compass testable. We can validate each component independently and stress-test the full system end-to-end.
How Compass Uses LLMs
Compass employs LLMs in four main ways:
- Conversational Engagement: Rather than waiting for questions from users, Compass drives a directed conversation by asking structured questions itself.
- Natural Language Processing (NLP): LLMs handle clustering, named entity extraction, and classification, making the system adaptive without requiring custom training.
- Explainability: Compass can link discovered skills back to specific user inputs, offering clear reasoning for its outputs (Technically: a form of Chain of Thought reasoning). This transparency allows users to verify and trust the skill identifications.
- Taxonomy Filtering: The LLM filters and refines outputs against localized versions of our inclusive skills taxonomy, which is based on the European Skills, Competences and Occupations (ESCO) classification—a standardized system used across Europe. (Technically: combining semantic search with reasoning.) This ensures identified skills match labor market realities.
These four functions create multiple evaluation points—from checking how accurately information is extracted to verifying that skill explanations trace correctly back to user inputs.
Balancing Flexibility with Structure
The way Compass uses LLMs creates an inherent tension: the system must be flexible enough for users to describe their experiences naturally, yet structured enough to reliably extract skills into our taxonomy. This balance directly shaped our evaluation approach. On one hand, overly rigid prompts would make conversations feel mechanical and fail to capture the diversity of jobseekers’ experiences. On the other hand, too much flexibility could lead to inconsistent outputs, missed information, or skills that don’t map to labor market categories. This tension meant we couldn’t simply evaluate Compass on accuracy alone. We also needed to test:
- Conversational quality: Does the system adapt to different communication styles while staying on track?
- Information coverage: Does flexibility lead to gaps in data collection?
- Output consistency: Do similar experiences produce comparable skill identifications?
Recognizing this design challenge early reinforced our pragmatic, multi-stage evaluation approach—one that tests both what the system does (the outputs) and how it does it (the conversation quality). This became a recurring theme we carried forward into product and user evaluation, which we’ll cover in future posts.
Guardrails Against Hallucination
Fluent doesn’t mean safe. To reduce hallucinations and inaccuracies, Compass applies multiple safeguards at the architecture level:
- Task decomposition into smaller agent-specific prompts
- Context-aware instructions that adapt prompts based on conversation state
- Guided outputs using few-shot learning, Chain of Thought reasoning, Retrieval-Augmented Generation (RAG), JSON schema validation, and ordered dependencies
- Rule-based state guardrails that apply deterministic logic wherever possible
- Taxonomy grounding to ensure identified skills remain relevant to labor market data
These architectural safeguards reduce but don’t eliminate risk—which is why each measure is itself subject to evaluation. Every new prompt, schema, or taxonomy update must pass through our validation process before deployment.
Compass’s Model Evaluation Strategy
Our evaluation approach evolved alongside Compass itself. We couldn’t define a comprehensive testing strategy upfront because we didn’t yet know all the specific tasks the system would need to perform. Instead, we took a pragmatic, bottom-up approach: starting with the most fundamental requirement we understood—that Compass needed to handle complete conversations with users—and building evaluation methods iteratively as the system’s capabilities became clearer. Early on, we focused on end-to-end simulated user interactions because this was the one requirement we could articulate clearly. As development progressed and we discovered what specific tasks Compass needed to perform—extracting structured data, managing conversation memory, coordinating between agents—we added targeted tests for each capability. Simple metrics for individual components grew more sophisticated as the system matured. This incremental process resulted in seven core evaluation methods. Below, we describe each method, explaining what we evaluate, why it matters, how we test, and what we measure.
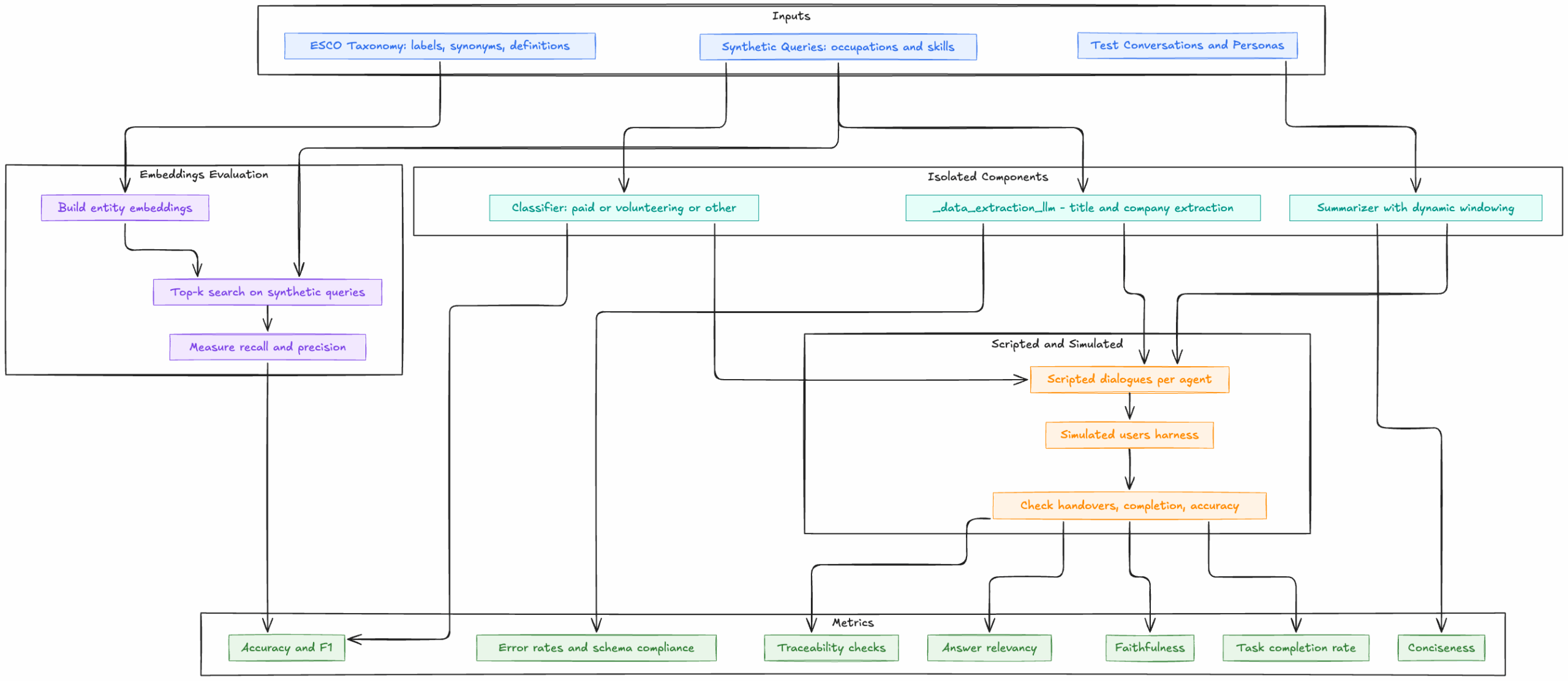
Overview of Compass Model Evaluation
1. Synthetic Query Testing
- What we evaluate: Compass’s ability to match user-described experiences to standardized taxonomy entries (occupations and skills from our inclusive livelihoods taxonomy, based on ESCO).
- Why it matters: If the embedding search fails, a user who says “I help repair tractors on the farm” might not be matched to “agricultural machinery technicians,” (ESCO 7233.8.1) and miss relevant career pathways. A query like “I am really good at Java and Type Script” should link to specific, multiple ESCO skills like Java and TypeScript.
- How we test: We created 542 synthetic occupation queries and 1,054 synthetic skill queries that mimic how jobseekers naturally describe their work. For each query, we verify whether our embedding search finds the correct taxonomy match in the top-k results.
- What we measure: Recall—can the system find the right match? We optimize for recall because it’s better to surface too many possibilities (which we can filter later) than to miss the correct match entirely. You can learn more about our evaluation framework in this Jupyer notebook.
2. Isolated Component Testing
- What we evaluate: Compass is built from multiple specialized tools, each with a specific function. For example, one tool classifies experiences as “paid work,” “volunteering,” or “personal projects.” Another extracts structured data (job titles, companies, dates) from natural language descriptions. Isolated component testing evaluates each of these tools independently against known outputs.
- Why it matters: Each tool must perform reliably before we can trust the full pipeline. A faulty classifier could miscategorize volunteer work as paid employment, affecting skill identification.
- How we test: We run known inputs through each tool and verify the outputs match expectations. For the data extraction tool, we input: “I sell shoes at the local market on weekends.”
- What we check: The extracted experience should contain: title (“selling shoes” or similar), entity (“local market” or similar), timing (reference to regular frequency, on weekends).
3. Summarization Testing
- What we evaluate: Compass’s dynamic conversation summarization, which keeps recent exchanges verbatim but condenses older content to manage context window limitations.
- Why it matters: Poor summarization could lose critical information or distort conversation history, leading to confused or inaccurate follow-up questions from Compass.
- How we test: We created hand-crafted test conversations with known content and ran them through the summarization process. Both human reviewers and automated evaluators (LLMs) assessed the summaries.
- What we measure: Consistency (does the summary remain stable across iterations?), relevance (are key details preserved?), and accuracy (does the summary faithfully represent the conversation?).
4. Scripted Dialogue Testing
- What we evaluate: The conversational flow between agents and the quality of agent-to-agent transitions—does each agent collect the right information and pass control appropriately to the next agent?
- Why it matters: Compass’s multi-agent architecture only works if agents smoothly hand off to each other and collectively gather complete information. Poor transitions could create repetitive questions or skip critical data.
- How we test: We run predefined dialogue sequences through the conversational agents and have outputs reviewed by automated evaluators (other LLMs) and human inspectors. For example, for the experience collection agent: “Hi, can you explain the process?” → “I worked as a baker” → “pastry and bread making” → “I started in 2012.”
- What we check: Proper agent transitions, complete data extraction, appropriate conversational responses, and whether the system stays on track throughout the dialogue.
5. Persona-Based Simulation
- What we evaluate: End-to-end system behavior with realistic user personas, testing both complete conversations (from greeting to CV generation) and partial flows (like just the experience capture phase).
- Why it matters: Individual components might work in isolation but fail when integrated. Real users don’t follow perfect scripts—they ask questions, provide incomplete information, or go off-topic. We need to test whether Compass handles realistic variation.
- How we test: An automated test driver plays simulated users based on personas derived from UX research in South Africa, Kenya, India, and other regions. These virtual users engage Compass while the system automatically checks for expected behaviors.
- What we measure: Conversation completion rate, correct agent handovers, response conciseness, accuracy of extracted skills.
6. Wizard of Oz Testing
- What we evaluate: Early validation of conversation design and user experience with real users, before full system deployment.
- Why it matters: This method bridges model evaluation and product evaluation—it tests whether our conversation design works in practice while gathering insights for refining our testing personas.
- How we test: We ran a small WhatsApp study with users in Kenya where a developer manually simulated Compass’s replies. Participants believed they were conversing with an AI.
- What we learned: We refined our simulated user personas and validated aspects of conversation design, including typical conversation length and timing. We’ll discuss this stage in more depth when we cover product and user evaluation in future posts.
7. Real-World Pilot Testing
- What we evaluate: System correctness, output accuracy, and transparency in real deployment conditions with actual users.
- Why it matters: Real users stress-test the system in ways no simulation can fully anticipate. Manual review of actual conversations reveals edge cases, failure modes, and areas for improvement.
- How we test: Compass was tested with small groups of users in controlled environments. Our team manually reviewed over 1,000 conversations from the pilot, checking that the system performed as intended and didn’t misbehave. We traced skills outputs back to user inputs to validate accuracy and transparency.
- What we measure: We built feedback mechanisms directly into Compass where users can react to specific messages—flagging issues like offensive content, biased outputs, or inaccurate information. These direct user reports serve as an additional safety check.
Our Measurement Approach
Evaluating a complex conversational AI system requires different metrics at different stages. Rather than applying a single standardized scorecard, we selected metrics that matched what we needed to learn at each point.
- For accuracy and correctness: Precision and recall (particularly for taxonomy matching, where we prioritized recall to avoid missing relevant skills), F1 scores (for classification tasks like categorizing work experiences), error rates (tracking both LLM-specific failures and overall system failures).
- For safety and reliability: Faithfulness (ensuring responses stay grounded in what users actually said), traceability (verifying every identified skill links back to specific user inputs), schema compliance (checking outputs match expected formats).
- For conversation quality: Conciseness (ensuring responses were clear and avoided unnecessary repetition), answer relevancy (measuring how directly responses addressed user inputs), task completion rate (tracking the percentage of conversations that successfully resulted in skill identification).
For subjective dimensions like relevance or conversation quality, we used a combination of human judgment and LLM-as-a-judge evaluation—where one LLM assesses another LLM’s outputs against defined criteria. This hybrid approach let us balance scalability with nuanced assessment.
What’s Next
We’ve shared how we validate Compass’s technical foundations. But does it actually work for users? In our next posts, we’ll cover user/product testing in Kenya and impact evaluation in South Africa.
Join the conversation: Compass is open source on GitHub, with documentation here. We built it to be adaptable for anyone working on skills discovery or career guidance. We’d love to hear from you—whether you have questions about our evaluation approach, want to contribute to the code, or are thinking about building on Compass for your own context. Reach out at hi@tabiya.org.
Technical Backbone
Compass’s architecture is supported by a modern technical stack:
- Models: Gemini-2.0-flash-001 for conversations, text-embedding-005 for embeddings, Gemini-2.5-pro-preview-05-06 for automated evaluations.
- Backend: Python 3.11 with FastAPI and Pydantic for asynchronous, high-performance processing.
- Frontend: React.js, TypeScript, and Material UI, optimized for mobile users.
- Data Persistence: MongoDB Atlas with vector search, storing both user data and taxonomies.
- Deployment: Google Cloud Platform, with Pulumi for infrastructure management and Sentry for monitoring.